작업 날짜 : 2022-08-31
작업환경 : python 3.10.2
작업 라이브러리 버전 : selenium 4.3.0
@app.route('/test_page')
def test_page():
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get("https://test_link.com")
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.find_element_by_class_name("_productSet_hotdeal").click()
...파이썬 셀레늄을 통한 크롤링을 웹
라이브러리인 플라스크를 통해 구현하던 중
어찌 된 영문인지 find_element_by_class_name 속성이 작동하지 않았습니다.

find_element_by_class_name 속성 에러 발생

역시 한국 구글링을 죄다 에러에 대한 내용은 없고 자기들이 사용했다는 걸 올려 둔 글 밖에 없어서
스택 오버플로우로 들어가 보니
Selenium - Python - AttributeError: 'WebDriver' object has no attribute 'find_element_by_name'
I am trying to get Selenium working with Chrome, but I keep running into this error message (and others like it): AttributeError: 'WebDriver' object has no attribute 'find_element_by_name' The same
stackoverflow.com
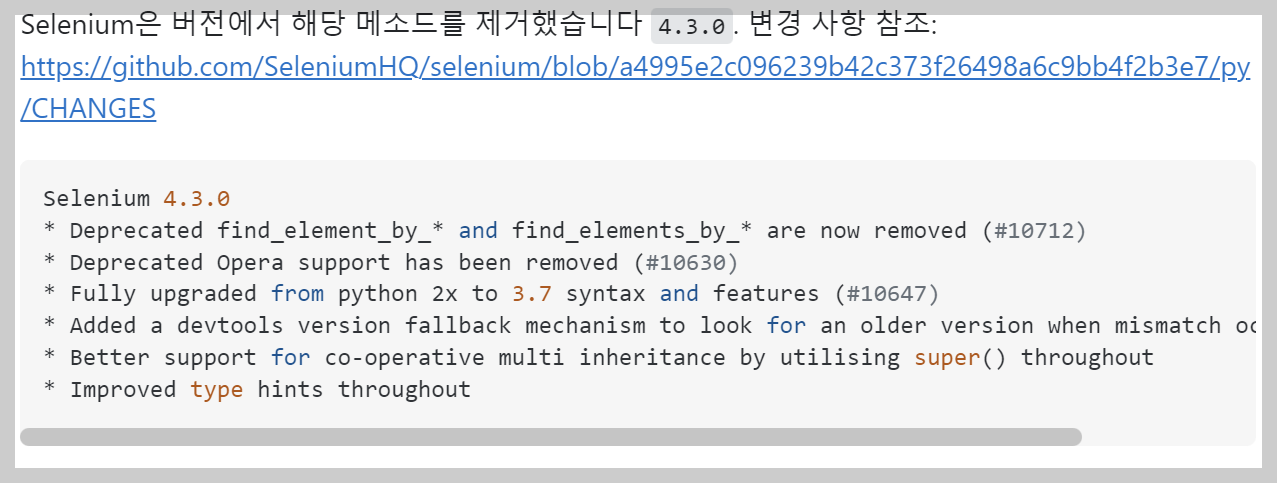
결론은 find_element_by_* 그리고 find_elements_by_* 메서드가 전부 삭제되었다고 합니다.
즉 다른 함수로 대체 사용해야 합니다.
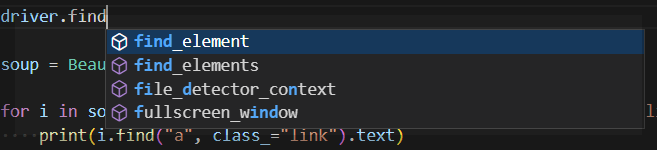
실제로 삭제된 듯합니다.
혹시나 저처럼 헤매시는 분들이 계실까 봐 글을 작성했습니다.
find_element_ 나 find_elements_ 속성의 하위 메서드를 사용하시는 분들은 전부
find_element/find_elements 메서드로 대체해서 사용하시길 바랍니다.
위 스택오버플로우 게시글 답변에도 대체해서 사용하라고 합니다.
다른글
중간값 구하기 알고리즘 (Python_Algorithm, median)
중간값 구하기 알고리즘을 Python으로 구현해보자 중간값을 구하려면 비교할 수 있는 수가 최소 3가지는 되어야 확인이 가능하다. 그 전에 코드가 난잡해지는걸 방지하기 위해 모듈 하나를 만들
hobbylists.tistory.com
무신사 홈페이지에서 키워드 수집해오기 (Python_Crawler) BeautifulSoup
Crawler(크롤러)란? 크롤러는 땅을 파는 굴삭기를 이르는 명칭으로 최근에는 웹에서 정보를 자동화된 방식으로 수집하는 걸 웹 크롤러라고 부른다. 그렇다면 크롤러란 프로그램을 사용해서 얻을
hobbylists.tistory.com
체레미 마카 마사지 캔들 포레스트 문 - 비건 마사지 캔들, 체레미엄 후기
체레미 마카 브랜드를 이용하다가 [체레미엄] 이라는 체험단을 모집하는 걸 보고 1기에 신청을 넣었으나 탈...
blog.naver.com
'개발&코딩 > Python' 카테고리의 다른 글
| 파이썬 패키지 설치 및 관리하는법 - pip (0) | 2022.09.19 |
|---|---|
| 파이썬 셀레니움 find_element의 InvalidArgumentException, NoSuchElementException 에러 이슈 관련 (1) | 2022.09.13 |
| 파이썬의 __init__() 의 역할 // python __init__(), constructor (0) | 2022.06.30 |
| 파이썬 내장 메소드 dir() 사용법 (0) | 2022.06.16 |
| 파이썬 버전별 출력법 + 기초적으로 숙지(제곱값, enumerate, range, 오버플로우) (0) | 2021.04.18 |



댓글