작업환경 : python 3.10.2
작업 라이브러리 버전 : selenium 4.3.0
일단 InvalidArgumentException 에러는 메서드에 제공된 인수가 유효하지 않을 때 발생하는 에러입니다.
즉 인수를 두개 받아야 하는 메서드에 인수가 하나만 지정되었거나 유효하지 않은 인수가 지정되었을 때 발생합니다.
NoSuchElementException 에러는 유효하지 않은(존재하지 않는) 요청을 받았을때 발생하는 에러입니다.
요즘 크롤링 공부를 해볼까 해서 인프런에서 크롤링 관련 인강을 듣는데
코드
from asyncore import write
from flask import Flask, render_template, request
import requests
from bs4 import BeautifulSoup
import time
#엑셀을 쓰기 위한 import
from openpyxl import Workbook
write_wb = Workbook()
write_ws = write_wb.active
#selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
browser = webdriver.Chrome(options=options)
app = Flask(__name__)
@app.route('/')
def hello():
return render_template('index.html')
@app.route('/result', methods=['POST'])
def result():
keyword = request.form["input1"]
page = request.form["input2"]
#https://search.daum.net/search?w=news&DA=PGD&enc=utf8&cluster=y&cluster_page=1&q=%EC%95%88%EB%85%95&p=1
#https://search.daum.net/search?w=news&DA=PGD&enc=utf8&cluster=y&cluster_page=1&q=%EC%95%88%EB%85%95&p=2
daum_list =[]
for i in range(1, int(page)+1):
req = requests.get("https://search.daum.net/search?w=news&DA=PGD&enc=utf8&cluster=y&cluster_page=1&q=' + keyword + '&p=' + page")
soup = BeautifulSoup(req.text, 'html.parser')
for i in soup.find_all("a", class_="tit_main fn_tit_u") :
daum_list.append(i.text)
for i in range(1, len(daum_list) + 1) :
write_ws.cell(i,1,daum_list[i-1])
write_wb.save("static/result.xlsx")
return render_template("result.html", daum_list = daum_list)
@app.route('/naver_shopping', methods=['POST'])
def naver_shopping():
search = request.form['input3']
search_list = []
search_list_src = []
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get("https://search.shopping.naver.com/search/all_search.nhn?query=%EC%9D%B8%EC%83%9D&cat_id=&frm=NVSHATC")
y = 1000
for timer in range(0, 10):
driver.execute_script("window.scrollTo(0, " + str(y) + ")")
y += 1000
time.sleep(1)
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.select("#_search_list > div.search_list.basis > ul > li") :
print(i.find("a", class_="link").text)
search_list_src.append(i.find("img", class_="_productLazyImg")["src"])
search_list.append(i.find("a", class_="link").text)
print("------")
driver.find_element("_productSet_hotdeal").click()
y = 1000
for timer in range(0, 10):
driver.execute_script("window.scrollTo(0, " + str(y) + ")")
y += 1000
time.sleep(1)
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.select("#_search_list > div.search_list.basis > ul > li"):
print(i.find("a", class_="link").text)
search_list_src.append(i.find("img", class_="_productLazyImg")["src"])
search_list.append(i.find("a", class_="link").text)
print("------")
driver.find_element("_productSet_overseas").click()
y = 1000
for timer in range(0, 10):
driver.execute_script("window.scrollTo(0, " + str(y) + ")")
y += 1000
time.sleep(1)
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.select("#_search_list > div.search_list.basis > ul > li"):
print(i.find("a", class_="link").text)
search_list_src.append(i.find("img", class_="_productLazyImg")["src"])
search_list.append(i.find("a", class_="link").text)
driver.close()
return render_template('naver_shopping.html',
search_list = search_list,
search_list_src = search_list_src,
len = len(search_list))
if __name__ == "__main__":
app.run(debug=True)아 이게 확실히 selenium이나 beautifulsoup등 크롤링 툴들도 변화가 정말 빠르고
크롤링해야 하는 웹의 트렌드(특히 네이버 ㅅㅂ) 정말 빨리 바뀌어서 그런가
인강에 나오는 코드로는 알맞은 결과를 얻어오기 힘들더라고요
이번에 selenium의 find_element() 메서드 때문에 특히 골머리를 앓았는데
이 코드를 작성하면서 계속 호환이 안되던 게 find_element() 이 메서드 하나였습니다.
이건 지난번에 작성한 글인데 기존에 사용되던 find_element_by_class_name 메서드가 삭제되고
그걸 find_element() 메소드가 대체하게 되었는데 이 기존에 사용되던 메서드는 인수를 하나만 받다가
find_element() 메소드는 인수를 두 개 지정해줘야 하는데 이게 머리가 아프더라고요
파이썬 셀레니움 find_element_by_class_name 삭제이슈관련 및 대체방법
작업 날짜 : 2022-08-31 작업환경 : python 3.10.2 작업 라이브러리 버전 : selenium 4.3.0 @app.route('/test_page') def test_page(): driver = webdriver.Chrome('./chromedriver') driver.implicitly_wait(3)..
hobbylists.tistory.com
InvalidArgumentException

아무튼 이번에 발생한 에러 또한 전부 find_element() 메서드를 제가 제대로 기존 인강 코드에서 변경해 작성을 못해서 발생했는데요
#기존인강코드
driver.find_element_by_class_name("_productSet_hotdeal").click()# 변경한코드
driver.find_element("_productSet_hotdeal").click()기존 인강코드에 사용되던 find_element_by_class_name() 메서드는 말 그대로 class이름만을 인수로 받는 메서드인데
find_element()는 값에 따른 속성과 인수 두 가지를 받습니다.
#class속성 값인 경우:
driver.find_element(By.CLASS_NAME, "username")
#id속성 값인 경우:
driver.find_element(By.ID, "username")
#name속성 값인 경우:
driver.find_element(By.NAME, "username")
#linktext속성 값인 경우:
driver.find_element(By.LINK_TEXT, "username")위 코드 예시처럼 말이죠
저는 find_element()에 값에 따른 속성 지정을 해야 하는 줄 모르고
_productSet_hotdeal이 값만을 인수로 하나만 지정해서 InvalidArgumentException 에러가 발생했습니다.
NoSuchElementException
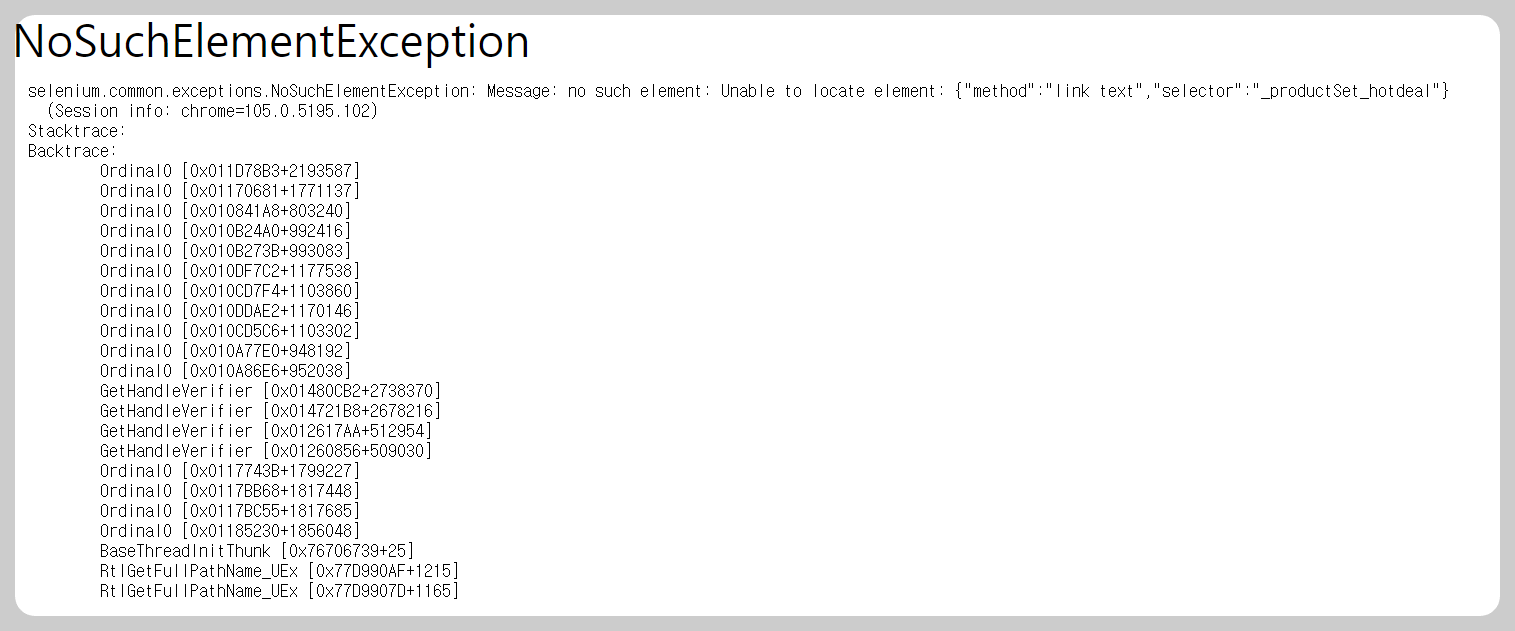
그래서 find_element()에 속성을 지정해줘야 하는 걸 알게 되었고
기존에 지정된 _productSet_hotdeal 속성이 find_element_by_class_name() 즉 클래스 이름을 사용하는 메서드에서 사용되었기 때문에
driver.find_element(By.CLASS_NAME,"_productSet_hotdeal")이렇게 지정했으나 _productSet_hotdeal은 클래스 이름이 아닌가 봅니다.
위 에러가 계속 발생합니다.
그게 아니라면 네이버의 핫딜 사이트의 웹 로직에 대한 변경점이 있어서 기존에 사용하던 위의 속성이 사라졌기 때문에
이 에러가 계속 나오는 것 같습니다.
참고-
selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: invalid locator error using find_element('userna
I am running python 3.9 with the following code. When I run the script I get the error message. Not sure what I am missing. The element is called username. File "/Users/user/Documents/
stackoverflow.com
'개발&코딩 > Python' 카테고리의 다른 글
| 파이썬 SyntaxError: Non-ASCII character '\xec' 에러 이슈 해결법 (2) | 2022.09.25 |
|---|---|
| 파이썬 패키지 설치 및 관리하는법 - pip (0) | 2022.09.19 |
| 파이썬 셀레니움 find_element_by_class_name 삭제이슈관련 및 대체방법 (1) | 2022.08.31 |
| 파이썬의 __init__() 의 역할 // python __init__(), constructor (0) | 2022.06.30 |
| 파이썬 내장 메소드 dir() 사용법 (0) | 2022.06.16 |



댓글